I lead data infrastructure and curation at Reve AI (company X).
My team is responsible for billion-scale multi-modal datasets and infrastructure for pre-training state-of-the-art image generation and editing models;
curating high-quality datasets driven by aesthetics and product needs (e.g., style, quality, control, safety, etc.);
and fine-tuning (frontier-scale) MLLMs for creativity and image generation.
See Reve Preview (Halfmoon),
Reve 1.0,
Reve 1.5,
and Reve 2.0 for details.
I enjoy travel and photography (link to section), especially in places with interesting history and landscapes.
Past Research
During my Ph.D., I designed systems and algorithms for understanding unstructured and unlabeled collections of images and video, focusing on novel applications of weak-supervision to scale data for real-world problems.
Learning Subject-Aware Cropping by Outpainting Professional Photos
James Hong, Lu Yuan, Michaël Gharbi, Matthew Fisher, and Kayvon Fatahalian
AAAI Conference on Artificial Intelligence (AAAI) 2024
Project website / Paper / Code
TL;DR: We turn a stock photo database into a weakly-labeled dataset for learning what makes an aesthetically pleasing composition. Despite being only weakly-supervsied, our system outperforms supervised methods trained on large, crowd-annotated datasets.
Learning to Place Objects into Scenes by Hallucinating Scenes around Objects
Lu Yuan, James Hong, Vishnu Sarukkai, and Kayvon Fatahalian
SyntheticData4ML Workshop @ NeurIPS 2023
Project website / Paper
TL;DR: We synthesize weakly-labeled scenes around objects using foundation models for image generation. By synthesizing a large number of scenes, we train a model that can better understand where objects can and cannot go.
Spotting Temporally Precise, Fine-Grained Events in Video
James Hong, Haotian Zhang, Michaël Gharbi, Matthew Fisher, and Kayvon Fatahalian
European Conference on Computer Vision (ECCV) 2022
Project website / Paper / Code
TL;DR: We propose an efficient neural network for processing every frame of a video to detect very temporally fine-grained events at the granularity of a single frame.
Video Pose Distillation for Few-Shot, Fine-Grained Sports Action Recognition
James Hong, Matthew Fisher, Michaël Gharbi, and Kayvon Fatahalian
International Conference on Computer Vision (ICCV) 2021
Project website / Paper / Code
TL;DR: We generate large amounts of dense weak-supervision on unlabeled and untrimmed sports video in order to learn more robust features for recognizing fine-grained actions.
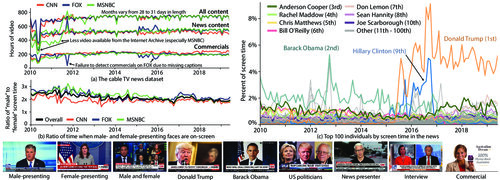
Analyzing the Faces in a Decade of US Cable TV News
James Hong, Will Crichton, Haotian Zhang, Daniel Y. Fu, Jacob Ritchie, Jeremy Barenholtz, Ben Hannel, Xinwei Yao, Michaela Murray, Geraldine Moriba, Maneesh Agrawala, and Kayvon Fatahalian
Conference on Knowledge Discovery and Data Mining (KDD) 2021
Project website / Paper / Code
TL;DR: We conduct an analysis of the visual content in 300,000 hours of US cable TV news. I built infrastructure to process the video and the TV news analyzer, a public interface and query engine for interactive search and visualization of all of the data.
Learning in situ: A Randomized Experiment in Video Streaming
Francis Y. Yan, Hudson Ayers, Chenzhi Zhu, Sadjad Fouladi, James Hong, Keyi Zhang, Philip Levis, and Keith Winstein
Symposium on Networked Systems Design and Implementation (NSDI) 2020
Project website / Paper / Code
Awards: USENIX NSDI Community Award, IRTF Applied Networking Research Prize
TL;DR: A public research platform for conducting video streaming experimentation. I designed the JS/HTML web client, which streams video and audio chunks over a websocket connection.
Rekall: Specifying Video Events using Compositions of Spatiotemporal Labels
Dan Fu, Will Crichton, James Hong, Xinwei Yao, Haotian Zhang, Anh Truong, Avanika Narayan, Maneesh Agrawala, Christopher Ré, and Kayvon Fatahalian
AI Systems Workshop @ SOSP 2019
Project website / Code
Prior to my Ph.D., I researched systems and networks for the Internet of Things, advised by Prof. Philip Levis.
Securing the Internet of Things With Default-Off Networking
James Hong, Amit Levy, Laurynas Riliskis, and Philip Levis
Conference on Internet of Things Design and Implementation (IoTDI) 2018
Paper
Tethys: Collecting Sensor Data Without Infrastructure or Trust
Holly Chiang, James Hong, Kevin Kiningham, Laurynas Riliskis, Philip Levis, and Mark Horowitz
Conference on Internet of Things Design and Implementation (IoTDI) 2018
Paper
Beetle: Flexible Communication for Bluetooth Low Energy
Amit Levy, James Hong, Laurynas Riliskis, Philip Levis, and Keith Winstein
Conference on Mobile Systems, Applications, and Services (MobiSys) 2016
Paper
Ravel: Programming IoT Applications as Distributed Models, Views, and Controllers
Laurynas Riliskis, James Hong, and Philip Levis
IoT-App Workshop @ Sensys 2015
Paper
Head of Data (Curation and Infra)
Research Assistant at Stanford University
Computer Science, Graphics Lab
Creative Intelligence Lab
Software Engineering Intern at Rubrik
Software Engineering Intern at LinkedIn
Data Analytics Infrastructure
Software Development Intern at PlayStation (SNEI)
CS 149: Parallel Computing
CS 248: Interactive Computer Graphics
CS 244: Advanced Topics in Computer Networking
CS 144: Introduction to Computer Networking
CS 224N/D: Natural Language Processing with Deep Learning
CS 161: Design and Analysis of Algorithms
17-09
18-03
18-11
19-03
19-08
19-11
21-07
21-08
22-08
22-10
23-03
23-06
23-07
23-09
23-11
23-12
24-02
24-03
24-06
24-08
24-11
25-07
25-09
25-10
25-11
26-02
26-04